
Most people misunderstand LangGraph. Here’s what it actually is
Internals.md #1 - A breakdown of how LangGraph works under the hood—and how to think about it in real systems.


Your agent worked yesterday. Today it’s returning wrong answers. No stack trace. No failed tool call. No exception. Just quietly incorrect output, shipping to production.
Here’s what probably happened. You added a node that writes to the same state key as an existing one, and LangGraph’s execution engine ran both in parallel. One write clobbered the other. The state is corrupt. Your agent looks fine because technically, it is running. It’s just running on a lie.
This post is about the engine that makes that possible and the one decision that prevents it.
Why Graphs Won the Agent Runtime
DAGs (Directed Acyclic Graphs) are elegant when data flows in one direction. The moment an agent needs to retry, re-plan, or loop through tool calls until some condition holds, they fall apart. A ReAct loop is not a DAG. It’s a cycle.
And cycles are what production agents actually do.
LangGraph’s answer is to model agents as cyclic graphs with typed state. Nodes compute. Edges - including conditional ones decide where execution goes next. State carries everything across steps. This isn’t a convenience; it’s the minimum structure that lets an agent loop without losing what it learned on the last pass.
The tradeoff is explicitness. You declare the schema up front. You declare the edges. The graph is compiled before it runs. In return, you get something most frameworks can’t give you: a runtime that pauses, resumes, replays, and parallelizes cleanly because the engine knows, precisely, what the graph is.
The Real Primitives: Actors and Channels
The public API shows you StateGraph, nodes, and edges. The engine underneath doesn’t work that way.
Before we go technical, here’s the mental model that makes everything else click.
💡 Mental Model: The Autonomous Pancake House
Stop thinking of a graph as a Boss shouting orders at Employees (function calling). Instead, imagine a kitchen that runs entirely on mailboxes (message passing).
The Channels (Mailboxes): There is a “Batter” mailbox and a “Plates” mailbox. They aren’t just boxes, they have rules written on the lid.
The Actors (Specialized Cooks): The Fryer cook doesn’t wait for a command. She sits by the “Batter” mailbox. The moment batter appears, she wakes up, cooks it, and drops the result into the “Plates” mailbox.
The Reducer (The Lid Rule): What if two cooks drop a pancake onto the same plate at once?
No reducer: The plate shatters; it only expects one item. (
InvalidUpdateError)With reducer (
operator.add): The rule on the lid says “Stack them.” Both pancakes land, and breakfast is saved.In this kitchen, no one talks to each other. They only talk to the mailboxes. This is why LangGraph can pause, resume, or run ten cooks at once; the state is in the mailboxes, not in the cooks’ heads.
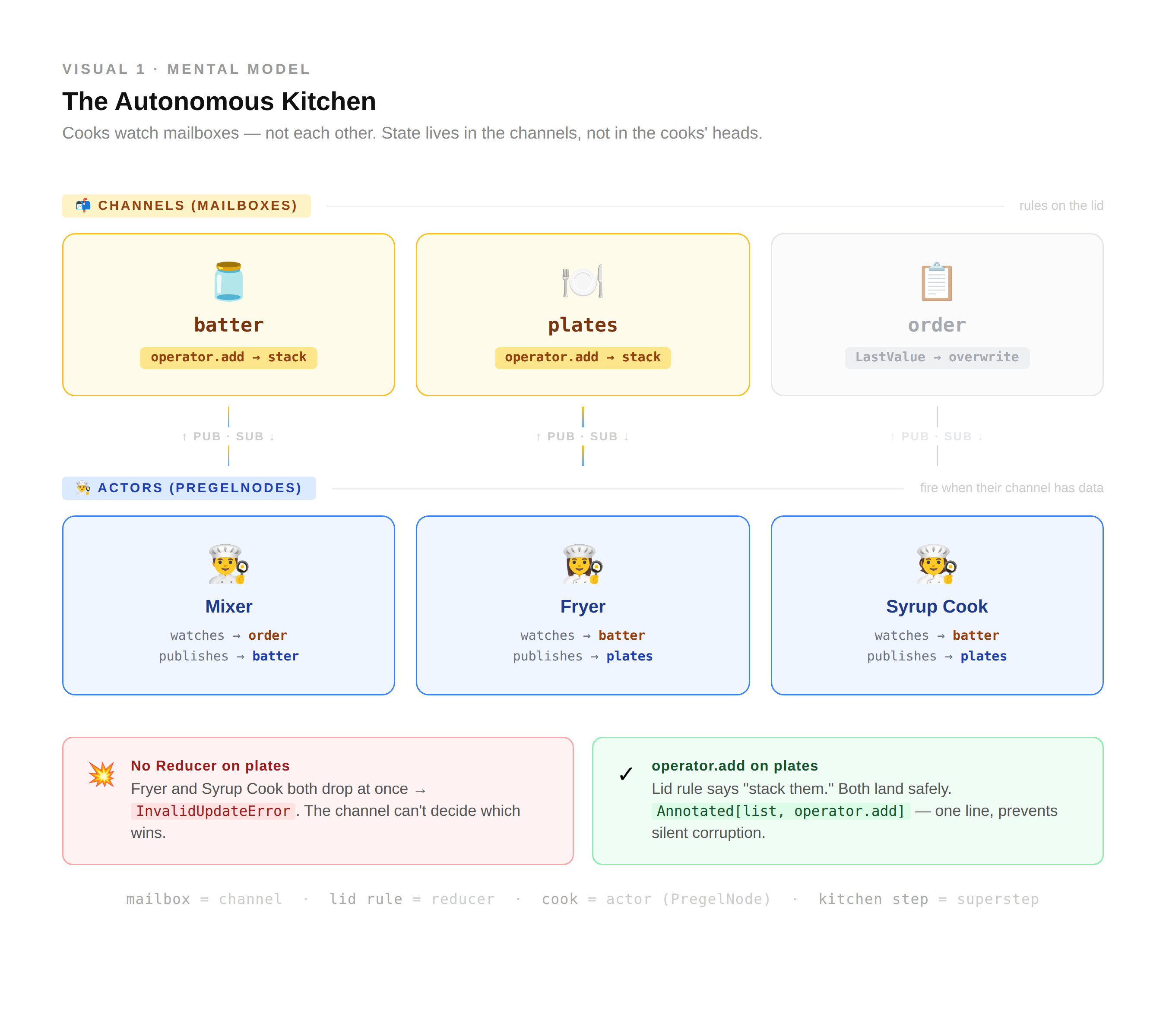
That's the mental model. Here's what it maps to in the engine.
Under the hood, LangGraph runs on a model borrowed from Google’s Pregel paper. Its real primitives are actors and channels. Actors called PregelNode internally subscribe to channels, read from them, and write to them. Channels hold values. Reducers decide how those values update when multiple writes arrive in the same step.
Here’s the reframing that matters: a state key in your StateGraph is a channel. A reducer is that channel’s update function. When you annotate a field with operator.add, you’re configuring the channel to append on update. When you leave it unannotated, the channel overwrites - and if two actors write to it in the same step, the engine throws.
So “state” is not a dictionary that nodes mutate. State is a set of channels, each with its own update semantics. Nodes don’t call each other; they publish to channels. Other nodes subscribe. This is message passing, not function calling.
Supersteps: The Execution Model
LangGraph executes in discrete steps called supersteps, and each one has three phases:
Plan: the engine inspects channel state and selects which actors to run
Execute: selected actors run in parallel
Update: writes are merged into channels through the reducers
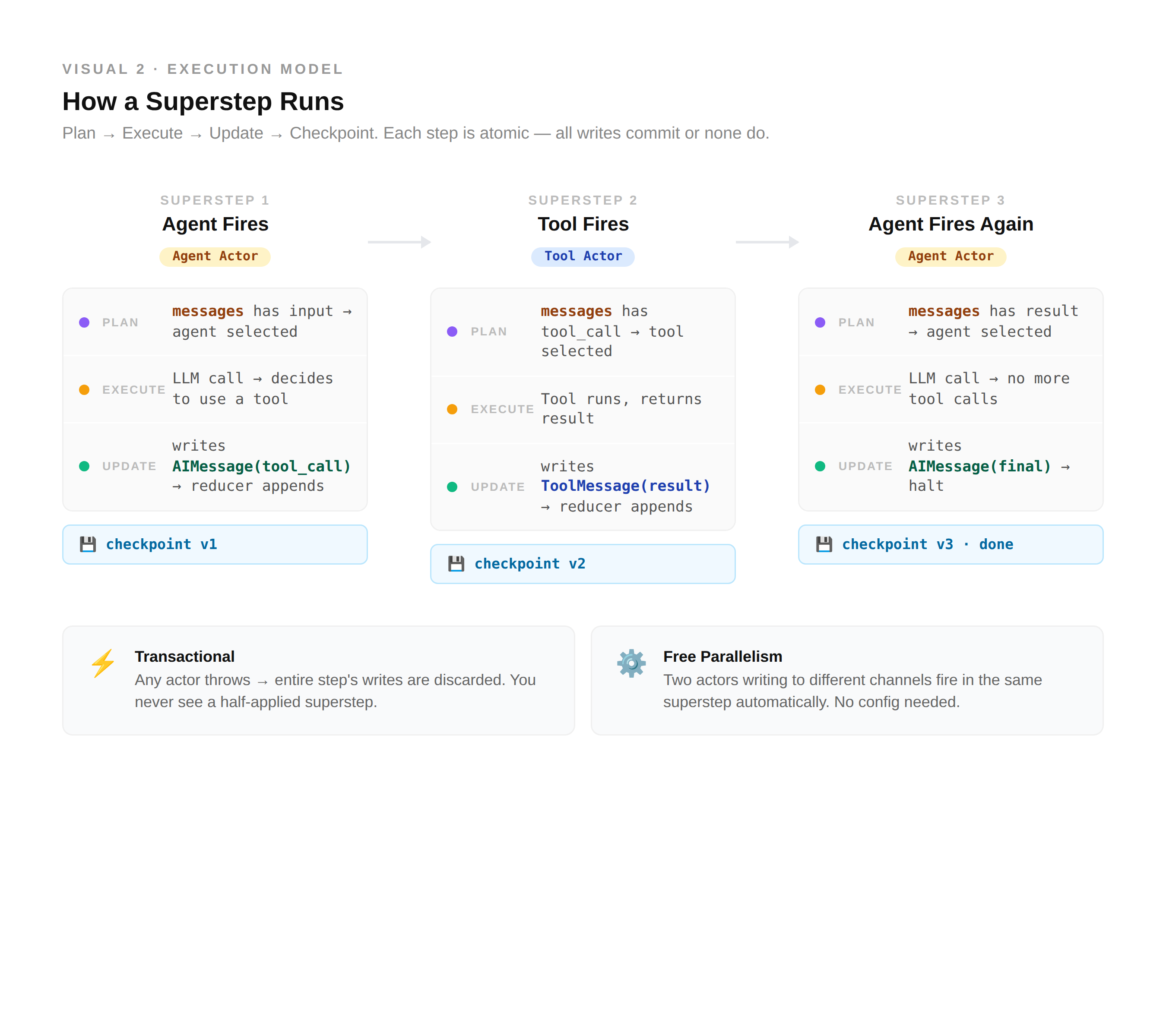
The crucial property is that a superstep is transactional. If any actor in the step raises an exception, the entire step’s writes are discarded. None of the parallel results land. This isn’t a bug - it’s the guarantee that makes checkpointing meaningful. You never observe a half-applied superstep.
Selection is deterministic, too. An actor fires only when a channel it subscribes to has new data. The engine loops until no actor has pending work, or a step limit is hit. This is Bulk Synchronous Parallel - the same model that powers Apache Spark’s graph processing layer.
Two consequences fall out of this design, and both matter at 2am in production.
First, parallelism is free when nodes are independent. If two nodes subscribe to the same input channel and write to different channels, they run in the same superstep with no extra configuration. The engine figures it out.
Second, concurrent writes to the same channel need a reducer. Without one, the engine has no way to know which write wins - so it refuses to guess.
That second consequence is where most production bugs live.
The Silent Corruption Problem
Here’s the error the runtime throws when you get it wrong:
InvalidUpdateError: At key 'todos':
Can receive only one value per step.
Use an Annotated key to handle multiple values.
This error is loud. It fires immediately. You see it, you fix it.
The silent version is worse.
If your graph has a single path today and no concurrent writes, the overwrite default works fine. You never see the error. Then weeks later - you add a parallel branch. A fan-out pattern, a subagent, a retry. Suddenly two nodes land writes in the same step. If the bug fires only intermittently, you get something uglier than an exception: wrong answers in production, with no trace of why.
The fix is one line:
from typing import Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, operator.add] # append, do not overwrite
todos: Annotated[list[Todo], operator.add]
This isn’t theoretical. It’s still happening in production frameworks. As of November 2025, running the official research example in deepagentsjs throws this exact error - the todos state key has no reducer, so the underlying channel falls back to LastValue, which refuses concurrent updates. The fix is the same in every case: annotate the channel with a reducer like operator.add so concurrent writes append instead of collide. CopilotKit shipped the identical patch for their LangGraph integration in August 2025 (PR #2276).
⚡ If you remember one thing from this post: every state key that could receive concurrent writes needs a reducer. The question isn’t whether you have parallel execution today. It’s whether you might add it next sprint.
Compilation: The Step Most Writers Skip
graph.compile() is not a convenience call - it’s where LangGraph turns your declarative graph into an executable plan.
During compilation, the engine does four things:
Validates that every conditional edge routes to a declared node
Builds the channel topology from your state schema and reducers
Constructs the actual
PregelNodeobjects from your node functionsFreezes the graph - the compiled object is immutable
What compile() returns is a Pregel instance. That’s what you invoke, stream from, and checkpoint. The StateGraph you built was a blueprint. The Pregel is the machine.
This matters because compilation errors are caught before a single token of inference runs. Return a value from a conditional edge that isn’t in the edge map, and compilation throws immediately — something like:
ValueError: Expected one of ['tools', 'end'], got 'tool'
Check your conditional edge return values.
Typo in an edge name. Zero LLM calls wasted. That’s the contract compile() offers - and most agent frameworks can’t give you anything close to it.
Checkpointing Is Write-Ahead Logging
Every database engineer already knows how checkpointing works, even if the docs don’t put it that way. LangGraph’s checkpointer is write-ahead logging applied to agent state.
After every superstep, the full channel state is serialized and persisted. On resume, the engine reads the latest checkpoint and continues from the superstep boundary. Simple idea, enormous consequences.
The persisted object is a Checkpoint - a versioned snapshot containing channel_values, channel_versions, and any pending writes from nodes that succeeded while a sibling was failing. The thread_id is the namespace key: one agent session, one thread. Different threads can’t see each other’s state.
One primitive, four use cases - really the same capability wearing different clothes:
Durable execution - crash mid-run, resume from the last checkpoint, lose nothing
Human-in-the-loop - interrupt before a node, serialize, wait for approval, resume
Time travel - load any historical checkpoint, replay from there, fork alternate paths
Partial failure recovery - if one node fails mid-step, the completed parallel writes get stored as pending; on resume, only the failed node re-runs

The Postgres checkpointer shows the mechanics clearly. It maintains four tables. checkpoints holds state snapshots as JSONB. checkpoint_blobs holds large values as binary. checkpoint_writes logs pending writes from mid-step failures. checkpoint_migrations tracks schema versions. Each superstep is an insert; resume is a read of the latest row for a given thread_id.
The trap is write amplification at scale. A long-running agent with a growing message list writes the full state every superstep. If messages accumulate unboundedly and checkpoints fire every step, checkpoint size grows linearly with conversation length.
One developer documented four-second reads on long threads in their production chatbot - the pickled message history sitting in checkpoint_blobs had grown large enough that loading a conversation meant a database query, a binary download, and a full pickle deserialization before the UI could render.
The fix is to evict. Summarize old messages, offload large tool results, keep the hot state small. DeepAgents handles this with a SummarizationMiddleware that compacts conversation history once token usage crosses a threshold. That’s the pattern in one sentence: checkpointing is cheap only if the state stays bounded.
Subgraphs and the State Boundary Problem
Every production agent eventually outgrows a single graph. A planner calls an executor. A router dispatches to specialists. A retrieval pipeline feeds into a synthesis step. LangGraph handles this natively - a compiled graph is itself callable as a node inside another graph.
The mental model: a subgraph is a reusable block of graph. Think of it like a function - compile once, invoke from anywhere. Same runtime, same checkpointer, same supersteps. When the parent reaches the subgraph node, execution descends into the child, runs to completion, and returns to the parent’s next superstep.
The boundary is where it gets interesting
Parent and child have separate state schemas. They have to - otherwise every subgraph would inherit every key from every possible parent, and the schemas would explode.
When execution crosses the boundary, state must be mapped. LangGraph does this one of two ways:
If the schemas share keys, state flows through those keys automatically. The parent’s
messageschannel wires to the child’smessageschannel. Updates propagate.If the schemas don’t share keys, you pass state explicitly at invocation and transform the child’s output back into the parent’s shape. This is the boundary that silently breaks.
The failure mode: you write a subgraph with state key documents. Your parent has state key retrieved_docs. The subgraph runs, writes to documents, returns. The parent’s retrieved_docs is still empty. No error. No stack trace. Just a synthesis step running on zero documents, producing a confident-sounding but ungrounded answer.
The fix is explicit mapping:
def call_retrieval(state: ParentState) -> dict:
result = retrieval_subgraph.invoke({"query": state["user_question"]})
return {"retrieved_docs": result["documents"]} # explicit key mapping
Treat subgraph boundaries like API contracts. Declare them explicitly. Validate the output shape.
⚠️ Subgraphs ≠ Subagents
Don’t confuse structural organization with behavioral autonomy.
Subgraphs are about code hygiene. Nested graphs that keep your main graph from becoming a spaghetti monster. They share the same execution engine and flow state through explicit channel mappings.
Subagents are about context isolation. An autonomous loop with its own context window. It doesn’t just share state - it filters it, preventing context pollution where the messy reasoning of one specialist confuses the planner.
You use a subgraph when you want to repeat a pattern. You use a subagent when you want to delegate a problem.
DeepAgents: The Harness Around the Graph
LangGraph gives you the runtime. DeepAgents gives you the architecture.
A vanilla ReAct loop fails in four predictable ways: shallow planning, context overflow, context pollution, state bloat. DeepAgents is a direct answer to each.
It’s an open-source harness from LangChain - a CompiledStateGraph wrapped with four middleware layers, each solving one failure mode:
TodoListMiddleware -
write_todosforces the agent to decompose the task and write the plan into context before actingFilesystemMiddleware -
ls,read_file,write_file, and friends let the agent offload large content to a virtual filesystem. The prompt holds pointers, not pages.SubAgentMiddleware -
taskspawns an isolated subagent with its own context window. Only the final result returns. The messy middle stays hidden.SummarizationMiddleware - watches token usage, compacts history when it crosses a threshold. Keeps checkpoints cheap.
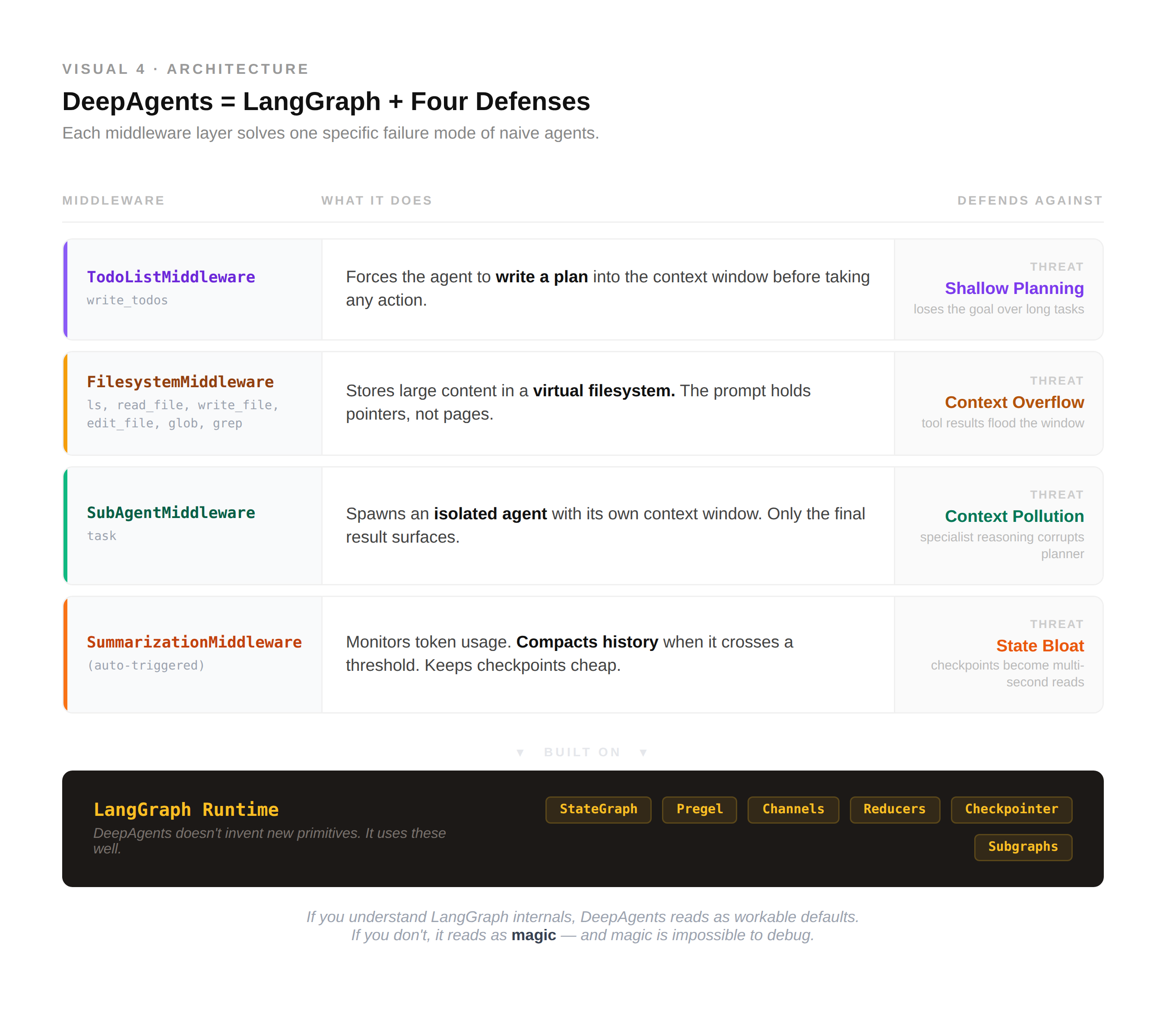
Notice what DeepAgents doesn’t invent. Every capability sits on top of LangGraph primitives - channels, reducers, checkpointing, subgraphs. DeepAgents isn’t a different framework. It’s a set of opinionated patterns for using LangGraph well at scale.
That distinction matters more than it looks. If you understand LangGraph’s internals, DeepAgents reads as a library of workable defaults. If you don’t, it reads as magic. And magic becomes impossible to debug the first time something breaks.
Five Failure Modes You Will See in Production
Every one of these is documented - in GitHub issues, official docs, or production writeups.
1. Concurrent write without a reducer. InvalidUpdateError: At key 'X': Can receive only one value per step. Two actors wrote to the same channel in one superstep without an annotated reducer. The engine refuses to guess which write wins. Fix: Annotated[list, operator.add] or a custom reducer. Sources: Official docs · deepagentsjs #65
This is the first bug every multi-agent system ships.
2. Empty update from a node. InvalidUpdateError: Must write to at least one of [...] A node returned nothing. Happens most often with conditional routing nodes that forget to return a payload on certain branches. Fix: Always return an explicit dict - even {"messages": []} satisfies the engine. Sources: langgraph #740 · langgraph #2644
The engine is strict by design — it would rather throw than guess.
3. State bloat at checkpoint time. Checkpoint reads in seconds, not milliseconds. Unbounded message lists, large tool results stored inline. Every superstep serializes the full channel state. Messages that grow without a cap grow the checkpoint linearly. Fix: Summarize or offload. Keep the hot state small. Source: lordpatil, July 2025 - four-second reads on a production chatbot, traced to checkpoint_blobs.
Checkpointing is only free if you treat state as precious. Most people don’t, until this.
4 & 5. Subgraph state silently not flowing / Serialization failures.
These appear less as sudden crashes and more as slow-burn confusion. Schema mismatch at a subgraph boundary (failure 4) produces no error - just a parent state that never updates, and an agent that silently runs on stale data. Fix: explicit key mapping at the invocation site. (Official subgraph docs)
Serialization failures (failure 5) fire during put_writes or resume: TypeError: Object of type X is not JSON serializable. The JsonPlusSerializer uses ormsgpack; anything it can’t encode breaks the checkpoint. Fix: keep only serializable objects in state, or use JsonPlusSerializer(pickle_fallback=True) for DataFrames and custom types. (langgraph #3441 · langgraph #5769)
Each of these is the kind of bug you ship without noticing. Each has a one-line fix once you see it. The difference between a senior engineer and a principal one on agent code is knowing which to check first.
What to Take Away
Three things that should survive this post.
LangGraph is a message-passing runtime with transactional supersteps - not a graph of function calls. Once you see channels and reducers as the real primitives, everything else follows: parallelism, checkpointing, subgraphs, even DeepAgents.
Every state key that might receive concurrent writes needs a reducer. The overwrite default is safe until it isn’t, and the failure mode is silent corruption.
DeepAgents is a library of patterns for managing the context budget. Planning, filesystem offloading, subagent isolation, summarization - four answers to the same underlying question: how do you keep the hot state small while the task stays long?
Next issue: Embeddings Internals. Why cosine similarity gets weird in high dimensions. What contrastive training actually learns. Why a general-web embedding model will silently fail on your domain data - and how to know when to fine-tune versus pick a better base model.
INTERNALS.md is a technical series on how production AI systems actually work. No tutorials. No framework evangelism. Just the layer beneath.
If this was useful, the best thing you can do is share it with one engineer who'd care.