
What you're actually writing when you write a SKILL.md
INTERNALS.md #2 · Skills are programs, not prompts. How the skills runtime actually loads, and why the architecture is everything.


A skill is a small program.
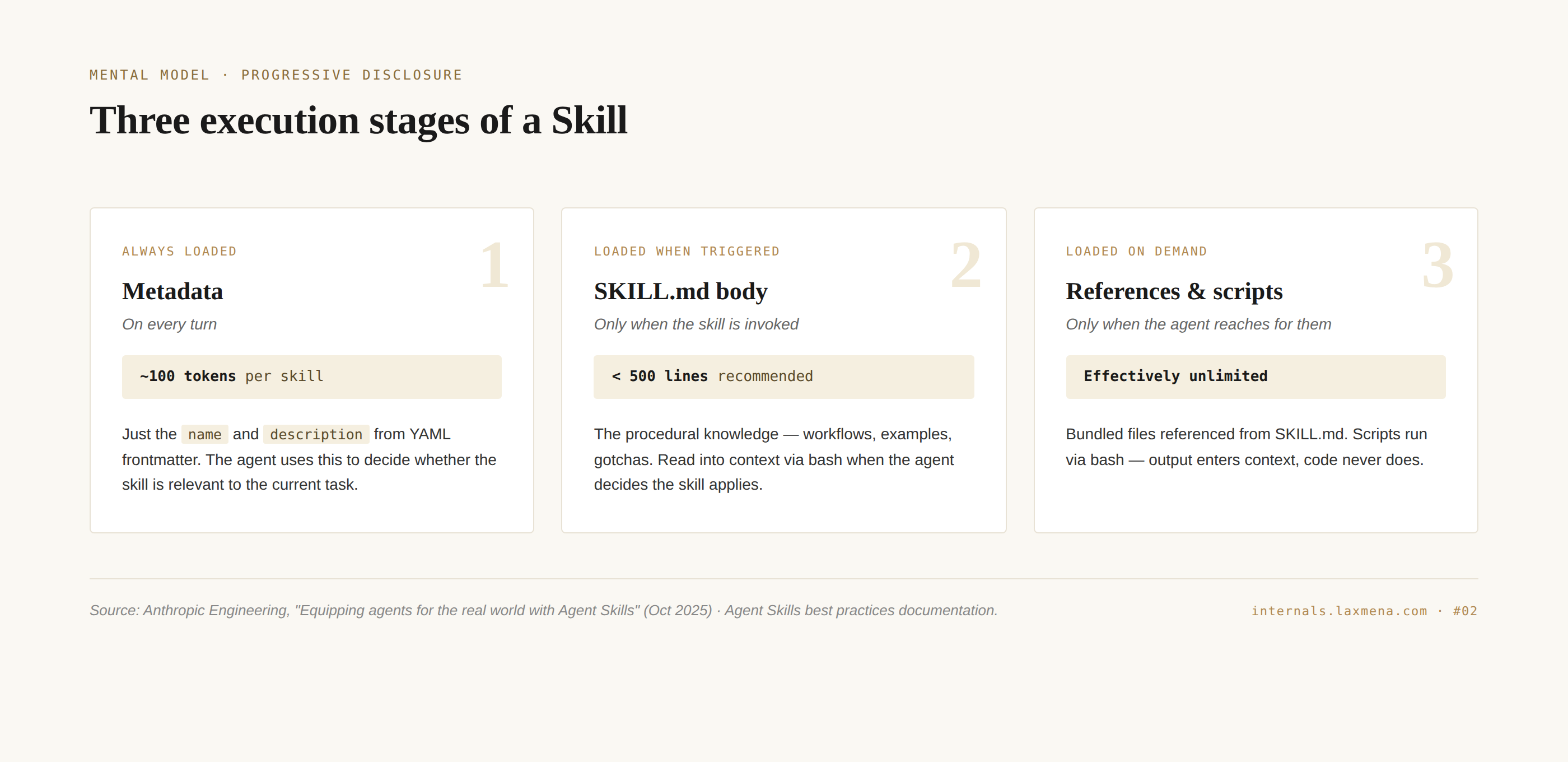
It has three execution stages: 1\ what loads every turn, 2\ what loads on invocation, and 3\ what loads on demand. Because a skill is a program, it suffers from typical software rot—environment drift, version sensitivity, and silent, non-reproducible failures.
You’ll see these failures in specific shapes. A skill that cost 20% of your context window, silently, before the agent did any work. A skill that worked perfectly until you shared it with a teammate, and ran the build in the wrong directory. A skill tuned carefully on one model, producing worse output the moment you upgraded to a better one.
These aren’t separate bugs. They’re four faces of the same misunderstanding: treating a loader specification like a prompt.
This post is about what skills actually are underneath, and why understanding the runtime changes everything you do at the surface.
A note on scope. Skills aren’t a Claude-only thing anymore. Anthropic published the SKILL.md format as an open standard in December 2025, and the same files now work across Claude Code, Kiro, Cursor, Codex CLI, and others. The mental model in this post applies to all of them. I’ll use Claude as shorthand for the agent harness reading the skill. Swap in your runtime of choice.
What skills are not
The first time I wrote a Skill, I thought I was writing a long prompt the agent would consult.
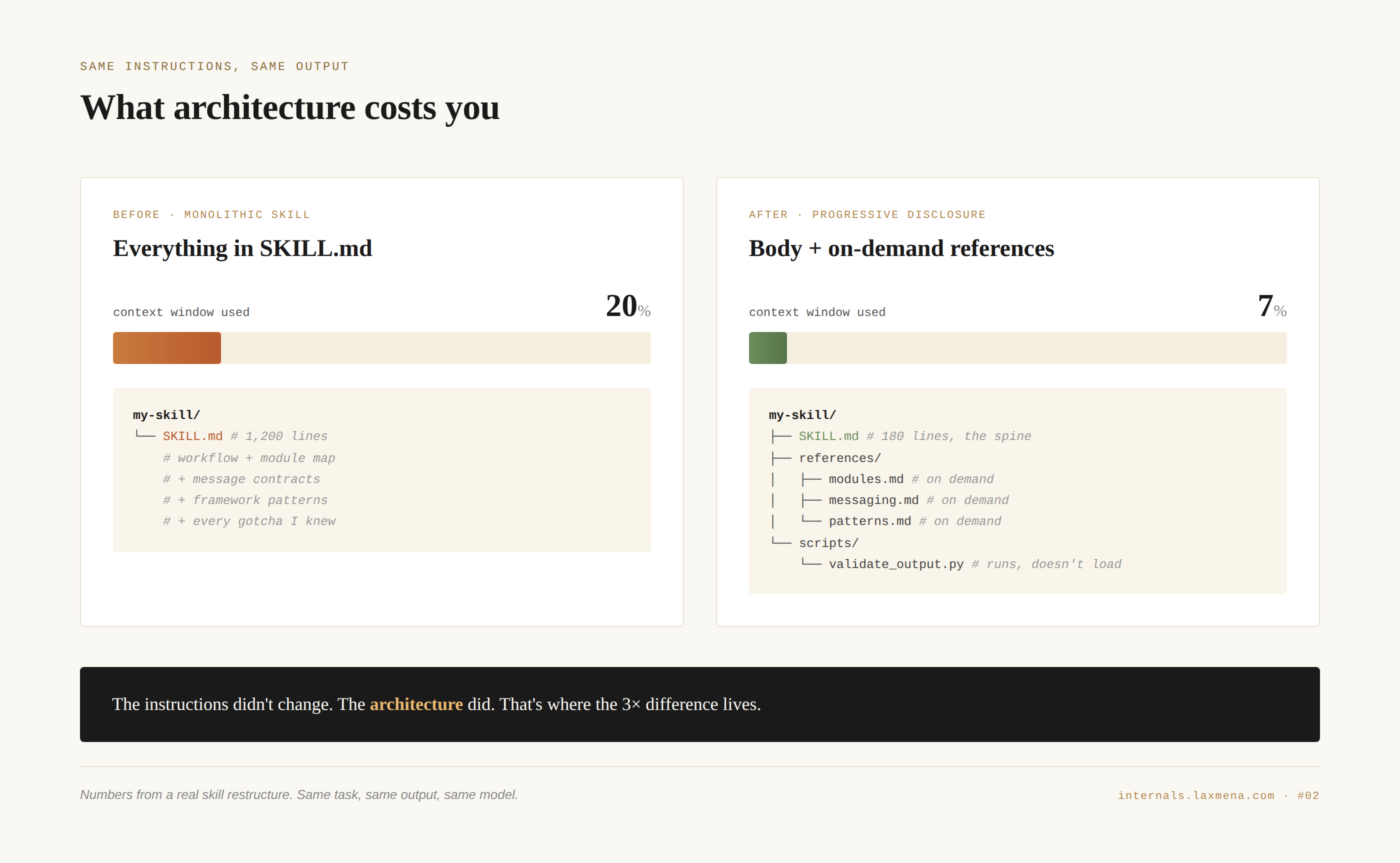
I wrote one big SKILL.md. Maybe 1,200 lines. Workflow at the top, a map of every module in our codebase, example code, message contracts between services, framework-specific patterns, and at the bottom a list of every gotcha I knew. It worked. It also consumed about 20% of the context window before the agent did any actual work.
I rewrote it. Same instructions, same output, different architecture: a 180-line SKILL.md that pointed at three reference files and one helper script. The new version cost 7%.
The instructions didn’t change. The architecture did. That’s where the 3× difference lived, and it was the first sign that I was not, in fact, writing a long prompt.
A prompt is static text. You write it, you ship it, the model reads all of it on every turn. Skills don’t work like that. Skills are a loader specification. You’re describing what should be in context, when, and at what cost. The text matters, but the structure decides what survives the trip into the model’s working memory.
That reframe is the whole post. Everything else falls out of it.
A real skill restructure. Same task, same model, same output. The 3× difference came from where the instructions lived, not what they said.
The runtime
Skills run on a principle Anthropic calls progressive disclosure. The official documentation defines it plainly:
Skills can contain three types of content, each loaded at different times.
This is why two skills with identical instructions can behave completely differently. One loads 180 lines on demand; the other dumps 1,200 lines every turn.
Anthropic built these levels to protect your context window. If a skill front-loads everything, it crowds out the conversation history and tool outputs. By using progressive disclosure, you stop paying for “just in case” instructions and only pay for “just in time” execution.
Each level loads at a different time, with a different cost. Most authors put everything at Level 2.
Level 1: Metadata. The name and description from YAML frontmatter. Always loaded, every turn. The official docs put this at roughly 100 tokens per skill installed. The agent uses the description to decide whether the skill is relevant. It’s a routing decision, not a usage decision. This is the most important level to get right. If the description is wrong, nothing else matters.
Level 2: SKILL.md body. The procedural instructions. Loaded only when the agent decides the skill applies, by reading the file via bash. Anthropic’s best practices documentation puts the recommended ceiling at 500 lines. This is where most people pile on content they shouldn’t.
Level 3: References and scripts. Bundled files referenced from SKILL.md. References are markdown the agent reads only when the body points to them. Scripts are executable code the agent runs: output enters context, the source code does not. Effectively unlimited.
The Anthropic engineering team (Barry Zhang, Keith Lazuka, and Mahesh Murag) described it in their October 2025 announcement as: “Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix, skills let Claude load information only as needed.”
Get the architecture right and your skill costs almost nothing until it earns its place. Get it wrong and you pay every turn.
Mental model
Picture a kitchen during dinner service.
The chef’s attention is the scarce resource. Same as the agent’s context window.
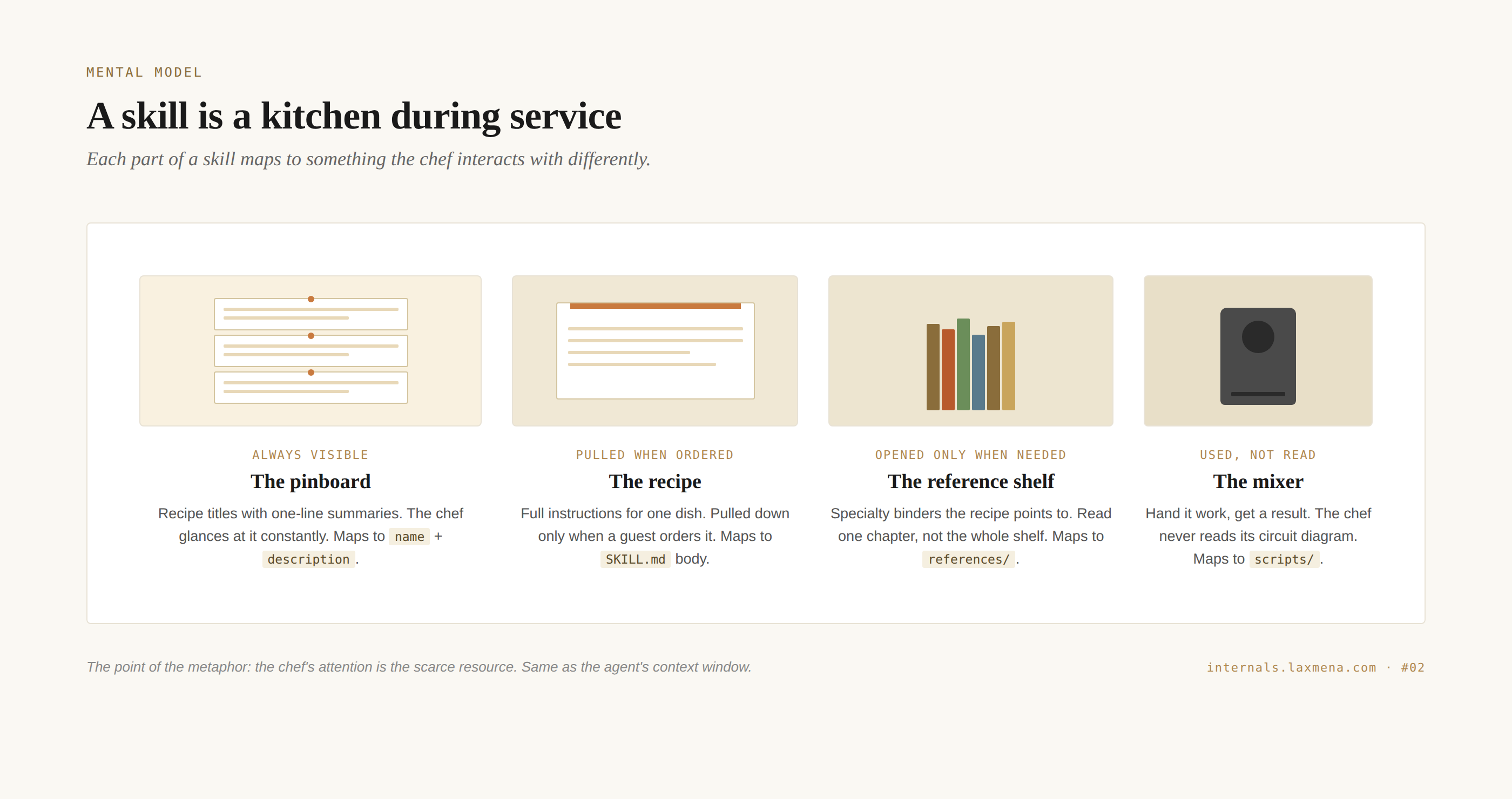
There’s a pinboard on the wall with recipe titles and one-line summaries. Pasta Carbonara: Italian classic, use when guest wants creamy pasta with bacon. The chef glances at it constantly. It’s small enough to hold in peripheral vision. That’s frontmatter.
When a guest orders, the chef picks the matching card and pulls down the full recipe. Ingredients, steps, technique notes. The recipe is not on the wall. It would be too cluttered, too distracting, too much to scan during service. It comes down only when needed. That’s SKILL.md.
The recipe sometimes says for the sauce, see Sauce Reference, page 47. The chef walks to the binder, opens to page 47, reads only that page. Doesn’t read the whole binder. That’s references/.
In the corner, a stand mixer. The recipe says use the mixer for three minutes. The chef does not read the mixer’s circuit diagram. The chef hands it ingredients, presses a button, gets output. That’s scripts/.
The metaphor holds under pressure, which is the only test of a metaphor. Every failure mode I hit in my own skills traces back to violating the kitchen.
The Antipattern Ledger
When I first started migrating my workflows to the SKILL.md, I treated the runtime like a smart intern who could “just figure it out.”
I was wrong. Because the skills runtime is a deterministic loader, minor architectural choices—like where you put a single line of YAML—can silently break the agent’s reasoning. These aren’t just bugs; they are antipatterns. Each one below represents a moment where I violated the “Kitchen” logic and paid for it in context drift, high latency, or hallucinated outputs.
Frontmatter on reference files
The first thing I got wrong, before I understood progressive disclosure existed.
I added YAML frontmatter to my reference files because SKILL.md had it, and the references felt important enough to deserve metadata. I didn’t realize what frontmatter actually does.
Frontmatter is what gets loaded into the system prompt at startup. Every file with frontmatter contributes its name and description to the always-loaded set. The pinboard. Adding frontmatter to a reference file pins it to the wall as if it were a top-level skill. It isn’t. Now the pinboard shows fifty entries instead of five, most of them sub-pages that were never meant to be visible at routing time.
In practice: the agent would occasionally trigger a reference file directly instead of the parent skill. Instructions out of context, without the skill body that gave them meaning. The output was subtly wrong and I couldn’t figure out why, because the reference file looked fine in isolation. I didn’t realize it had been promoted to skill-level visibility.
The fix was one line per file: delete the frontmatter from references. They’re not skills. They’re chapters that other skills point to.
One monolithic skill
This is the 20%-to-7% story.
When I built a skill to capture context across multiple modules and message systems, I put everything in one SKILL.md. It seemed cleaner. One file, one source of truth. Easy to read, easy to edit.
It also meant that every time the skill triggered, the agent loaded the entire 1,200-line file. Module map, contracts, patterns, and gotchas. Even when the task only needed two of those four.
Splitting it into a 180-line spine with three reference files dropped context consumption from 20% to 7%. Same task, same output, same model.
This compounds. A skill that costs 7% instead of 20% means you can install three of them in the same context budget, run longer sessions before compaction, hit fewer cliffs on long-horizon tasks. The savings aren’t local. They show up everywhere downstream.
Hardcoded workspace paths
I shared a skill with a teammate and it ran the build command in the wrong directory.
My instructions said something like navigate to modules/web and run the build. That worked in my repo. My teammate’s repo had four modules. modules/web didn’t exist; they had packages/frontend/web. The skill silently picked the wrong directory and produced output in the wrong place. No error. Just wrong output.
The fix was to write instructions that ask the agent to discover the right path rather than declare it. Search for the build configuration. Identify the module by its package.json. Read the workspace structure before assuming. The skill became more abstract, but it became portable.
This is the failure mode that doesn’t appear until you share. If you only ever run a skill on your own machine, you can hardcode anything and it will work. The moment another engineer runs it, every implicit assumption surfaces as a bug.
Missing gotchas
My monorepo uses Turborepo. The build command has to run from the repo root for the configuration to resolve correctly. If you run build from inside a module directory, the build still runs. But the cache misses, the dependency graph gets misread, and the output is subtly wrong.
The agent’s default was reasonable: I’m working in the web module, so I’ll run the build from the web module. That’s correct in 90% of repos. It was wrong in this one.
No amount of “explain the why” in the instructions would have prevented it. The wrongness wasn’t conceptual; it was environmental. The agent’s prior was correct on average. My environment wasn’t average.
The fix was a single line in a Gotchas section: Always run turbo build from the repository root, never from inside a module. One line. The next time the agent reached for the build command, it consulted the gotcha and ran correctly.
This is what Gotchas are for. The agent has reasonable defaults. Your environment isn’t average. That gap is the whole job of the Gotchas section, and it’s why mature skills treat it as the most important section to maintain over time.
Not knowing why the skill worked at all
The deepest mistake. I didn’t write evals.
I built a writing skill for my personal Claude desktop. It was based on Scott Adams’ writing principles: short sentences, active voice, front-loaded points, one idea per paragraph. I tuned it on Sonnet 4.6. It worked exactly the way I wanted: drafts came out clean, direct, in my voice.
Then I upgraded to Opus. Better model, I assumed. Better output.
The output was worse. Every sentence ran 5 to 7 words. Technically short. But choppy. No rhythm, no flow, nothing that read like me. The writing felt like bullet points dressed as prose.
What happened is subtle. Sonnet read “write short sentences” and applied judgment: short where brevity sharpened the point, longer where the rhythm needed it. It understood the spirit. Opus read the same instruction and followed it literally. Every sentence, hard constraint, no exceptions.
The more capable model has stronger priors about what “good writing” looks like. Its version of clear prose is the statistical center of good writing on the internet. My voice isn’t the statistical center. Opus pulled hard toward its own aesthetic, and away from mine.
A skill tuned on one model is calibrated to that model’s compliance characteristics, not just its capabilities.
A more capable model isn’t automatically a better fit. Sometimes it’s worse, because it interprets your instructions instead of following them.
I had no evals. No way to know how much had drifted, which instructions were being over-applied, or what a passing output even looked like quantitatively. I’d never defined what “sounds like me” meant in terms a test could check.
Anthropic’s skill-creator, the tool the team uses to build their own skills internally, has an explicit eval methodology. The core move is paired runs: for every test prompt, run the agent twice. Once with the skill, once without. You’re not measuring whether the output is good. You’re measuring whether it’s better than baseline, and by how much.
For a writing skill, not all assertions are scriptable. But some are: output length, sentence count, average sentence length, readability score. The rest is structured human review, with the previous output alongside the new one and a notes field. That’s what Anthropic’s eval-viewer in skill-creator produces.
I now keep a small 'Golden Set' per skill—a practice we’ll dissect in an upcoming post on automated skill validation—to ensure my voice doesn't drift when the underlying model changes. Three or four realistic prompts. Rerun the suite on every model bump, every skill edit. Check the deltas.
It worked when I tested it is not evidence. It’s the absence of measurement.
What survives the post
Four things should stick.
Skills are loader specifications, not prompts. Frontmatter is a routing mechanism. SKILL.md is a triggered payload. References and scripts are deferred chapters. Once you see the architecture, every authoring decision becomes a question of which level does this content belong at?
Architecture decides cost. The same instructions, in the wrong shape, can consume 3× the context window. That penalty compounds across every skill installed and every turn taken. The fix is structural, not prose-level.
The agent has reasonable priors. Your environment doesn’t. Gotchas exist because the model’s defaults are correct on average and your situation isn’t average. Workspace paths, build systems, team conventions: none of it lives in the model’s training. It has to live in the skill.
A model upgrade is not free. A skill tuned on one model is calibrated to that model’s compliance characteristics. A more capable model interprets your instructions instead of following them, and for skills that encode personal or organizational voice, that interpretation is the failure. The only way to know if an upgrade helped or hurt is to measure it.
INTERNALS.md is a technical series on how production AI and Data systems actually work. No tutorials. No framework evangelism. Just the layer beneath.
If this was useful, the best thing you can do is share it with one engineer who’d care.
Sources
Agent Skills overview, Claude API documentation
Agent Skills best practices, Claude API documentation
Equipping agents for the real world with Agent Skills, Barry Zhang, Keith Lazuka, Mahesh Murag, Anthropic Engineering, October 2025
skill-creator/SKILL.md, Anthropic skills repository
Agent Skills open standard, December 2025
The Day You Became a Better Writer, Lakshmanan Meiyappan
Scott Adams’ original post, via Internet Archive
This is a very interesting article, much appreciated.
This is a new thought to me. Thank you for writing this article!